
The Modern Agentic AI Infrastructure

At Decision Computing we have built an agentic workflow product which allows non-technical users to create powerful AI agents using simple drag and drop. These agentic workflows can handle all kinds of knowledge work from underwriting and claims processing in insurance to generating marketing content or automating RFQs. To ensure the AI agents are reliable and enterprise ready they require infrastructure that can provide:
- Scalable analytics over local data sources and remote data lakes.
- Transactional workflow runs.
- Replays of previous data through the same workflow.
- Auditing of workflow outputs.
- Persistence at scale.
- Efficient visualizations and data analytics.
In this post we will break down some of the core architectural building blocks we used to create a robust, scalable infrastructure.
Data transfer for agents
Agents need data transferred to them efficiently and their responses returned and forwarded to other components for further processing and storage. Apache Arrow with its efficient zero-copy columnar data transfer is a great choice as the data backbone. The Arrow project has extended from a core data definition format to defining how that data can be sent efficiently over the network (Arrow Flight protocol) and how data stores can provide and receive data with Arrow (Arrow Database Connectivity - ADBC).
There is a growing ecosystem of tools that can understand Arrow. For in-memory single node processing we chose DuckDB as the analytic engine which has an ADBC client contributed by the project itself. You can also forward this data to the edge with Arrow over http and run analytics within the browser with DuckDB WASM. This allows for an end to end data transfer and processing pipeline suitable for real-time analytics as well as our proprietary agentic AI components. All data clients can use DuckDB as needed with its various bindings: from browser (WASM), server (Golang ADBC), or Python models (DuckDB Python).

Ensuring persistence at scale
Next, persistence of the data produced by agentic steps at scale is required. The Data lakehouse is gaining traction with Apache Iceberg, Delta Lake and others. But recently DuckDB entered the arena with a radically simple offering: DuckLake. DuckLake needs two core components: an ACID database (for metadata) and a filestore (for core data files), for example Postgres with Amazon S3. DuckDB provides excellent optimized single node analytics but further optmizations can help including caching DuckLake remote files and intelligent sampling. These are topics we will discuss in a future post. The extended architecture can be viewed as follows:

DuckLake allows persistence for the analytical data created when running agents. It comes with nice features including “time-travel”, enabling you to go back to a previous snapshot. But, unlike batch analytics, agentic AI systems naturally emit many small incremental outputs. This means that lakehouse designs optimized for large commits become problematic. Luckily, DuckLake allows you to inline small data updates with the metadata and manually flush this data to storage at a later date. As a result, small parquet files don’t accumulate from isolated processing steps which can slow down query speed.
Dealing with scattered data sources
The stack described so far works well with traditional data sources from databases and bucket stores, but many enterprises have their source data in a wide range of systems. For example, HR data could be in Greenhouse, other data in simple Google Sheets, and so on. Recent studies (for example, Deloitte) have highlighted this challenge when applying AI agents to the enterprise. Ideally, one wants a uniform layer to receive and push messages that can connect with the landscape of enterprise tools and systems. Messaging systems can provide that uniform connection to enterprise data stores and tools. Kafka is one option which is used by many enterprises already, but there are alternatives like Redpanda, Apache Pulsar or cloud based messaging systems. There is also a wide ecosystem of companies specializing in handling data integrations (such as Airbyte, Fivetran or Estuary) and most support source and sink to messaging systems like Kafka. Adding this layer to our stack we have:
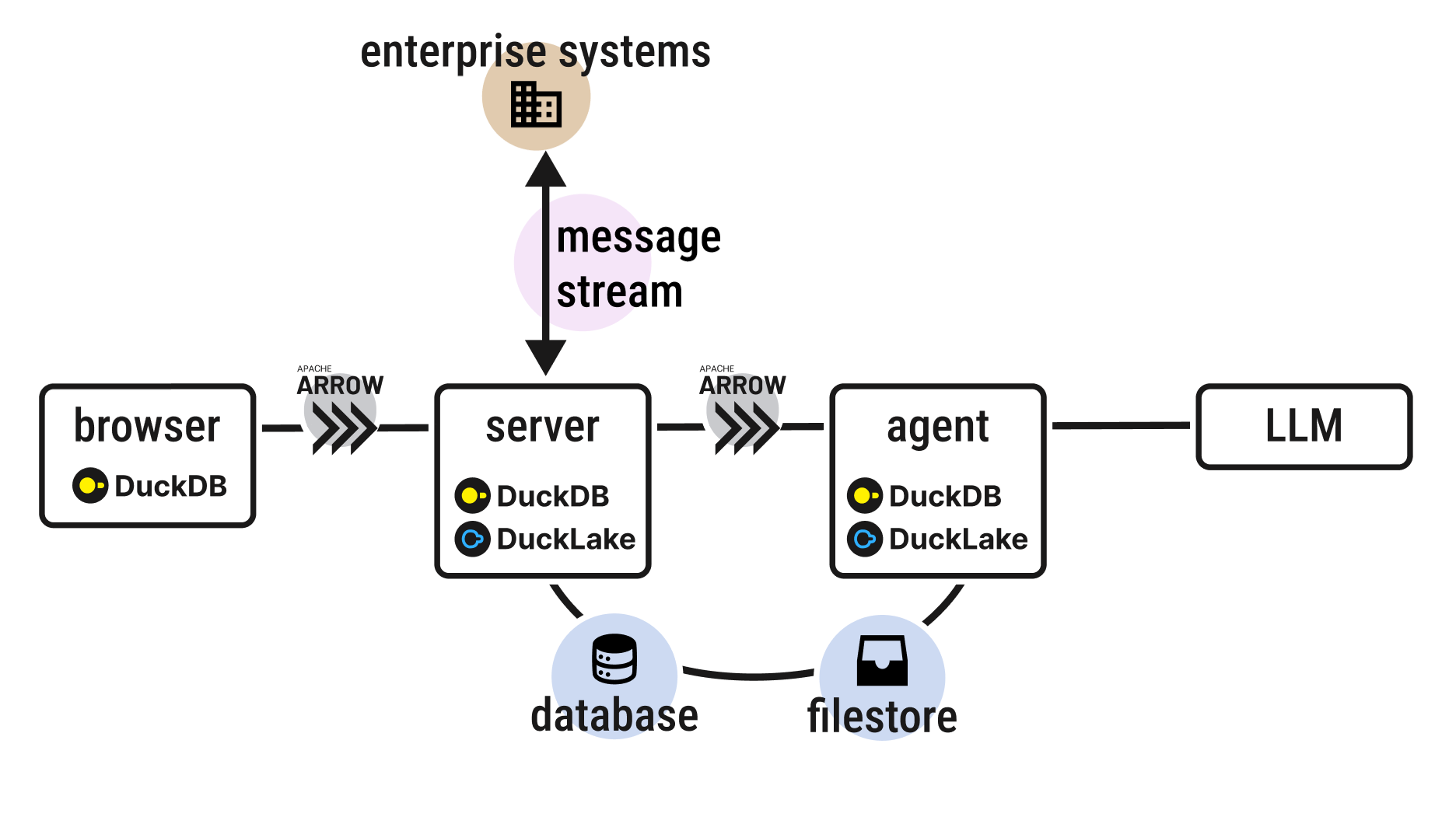
The use of a persistent messaging layer also has additional advantages:
- Message streams can be used to replay a sequence of inputs for validating and auditing agentic workflows and testing the performance of new agent versions.
- Workflows can be tied together into larger units allowing composability across teams and projects.
Taking it further
So far, we have only discussed part of what is required to run AI agents at scale for the enterprise. Our full agentic platform extends this stack with:
- Sampling and caching to make efficient querying of larger-than-memory datasets possible.
- Transactional processing of workflows with retry over failures allowing each workflow input to progress through a series of analytic, traditional machine learning and agentic LLM-based steps.
- Project-level data policy handling for different types of users.
- Auditing and exporting of workflow results as needed.
- Deployment with Kubernetes allowing both cloud and on-premise installation.
- … and much more!
In summary, Innovations such as efficient in-memory analytics with DuckDB, scalable lakehouse architectures and data movement solutions from Arrow to event streaming with Kafka provide a strong base for building scalable agentic AI solutions.
You can see an example of this stack in action discussed here - in a future post we will discuss the specific infrastructure components behind the scenes for this.
Ready for enterprise-grade agents in 2026?
Stop experimenting and start delivering. Get the production-ready agentic system you need for 2026 and beyond.
Legal
Privacy policyGet the latest product news and updates.